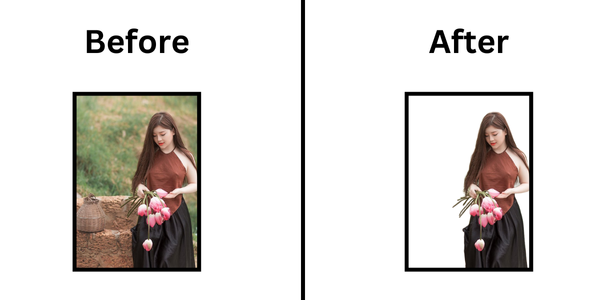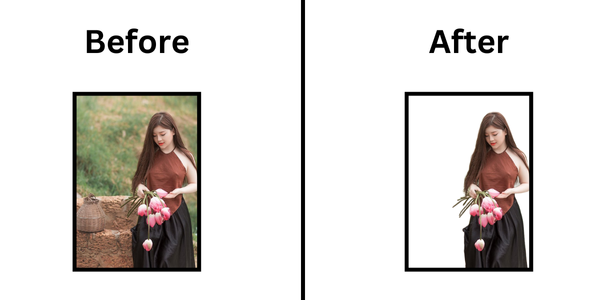
RMBG v2.0 is a new background removal model designed to effectively separate foreground from background in a variety of image categories and types. RMBG v2.0 competes with leading SOTA models in accuracy, efficiency, and versatility.
The BRIA Background Removal v2.0 model is designed to efficiently remove backgrounds from images, making it useful for various applications like e-commerce, photography, and graphic design.
RMBG-2.0 is built on the BiRefNet architecture and trained on over 15,000 high-quality, high-resolution, hand-labeled (pixel-perfect), fully licensed images.
▶️Here's a general guide on how you can use such a model in Python. Example code for running on Transformers:
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
from transformers import AutoModelForImageSegmentation
import requests
import io
model = AutoModelForImageSegmentation.from_pretrained('briaai/RMBG-2.0', trust_remote_code=True)
torch.set_float32_matmul_precision(['high', 'highest'][0])
#model.to('cuda')
# Check for GPU availability and set device accordingly
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}") # Print the device being used
model.to(device) # Move the model to the selected device
model.eval()
# Data settings
image_size = (1024, 1024)
transform_image = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# Define the path to your input image
input_image_path = "https://images.pexels.com/photos/1308881/pexels-photo-1308881.jpeg?auto=compress&cs=tinysrgb&w=1260&h=750&dpr=1"
# input_image_path = "/media/"
# Fetch the image from the URL using requests
response = requests.get(input_image_path, stream=True)
response.raw.decode_content = True # Ensure correct decoding
# Open the image using PIL's Image.open with io.BytesIO
image = Image.open(io.BytesIO(response.content))
# image = Image.open(input_image_path)
# input_images = transform_image(image).unsqueeze(0).to('cuda')
input_images = transform_image(image).unsqueeze(0).to(device)
# Prediction
with torch.no_grad():
preds = model(input_images)[-1].sigmoid().cpu()
pred = preds[0].squeeze()
pred_pil = transforms.ToPILImage()(pred)
mask = pred_pil.resize(image.size)
image.putalpha(mask)
image.save("bg-less-images.png")